在上面三節中,我們不外在學習一些準備知識,大概來說,我們想這樣做:
一般情況下我們假設某一社會現象服從某一型分佈函數,希望了解這個類型的分佈函數,可以進一步了解分佈函數的內涵。
但是,一個分佈函數裏面仍包涵著幾種特性,出現在概率函數的數學代表式中,
便是它的參數,例如在二項分佈中的P,
在波爾松型分佈的λ,和在常態分佈中的μ和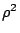 。 。
例如在上談到的全年國民收入中,我們可以假設這個收入是一個機隨變數,
它服從一個常態分佈函數(若次數很大,一般情形。用中心極限定理來逼近,說估計量趨近常態分佈也。)
但是我們不知道這個常態分佈函數的參數μ和是多少,我們仍要下功夫去猜測,
然後才能知道分佈函數,也就是說才知道原來的現象是怎樣。
一般說來,我們回到最原始找測度的問題了。參數是常數,最少也屬於由數據觀點看來的常數,
是可以由數據進而猜測決定的。所有參數皆是由測度決定的,雖然測度有時不止於參數,
(例如在無母分析上面。)但參數即使不是單由測度決定,也可以由他的函數所決定。因此,
我們由原始到結束,就說明了目的全在找「測度」,
整個統計就建立在猜測這個測度是什麼這個問題上。
在一個參數分析的方法上,過程是這樣子的:
假設我們所要知道的社會現象是服從某一型(如常態)分佈函數。
我們想確定一下它是一個怎樣子的常態分佈,那麼只要測度出參數是什麼就夠了。
因為參數一定,整個分佈函數就定下來了。
許多情形也可以證明不需要全部應用所有數據,我們只需從母數數據中,
抽出一部份隨機而具代表性的樣本,從這樣來找出一些統計量,來測度那些參數的值。
這樣子已到了統計推論了。推論的意思自然和由小樣本推論到大樣本。
另一方面也是為了利用測度來預測參數乃至整個分佈函數。我們舉推論的常用方法為例。
- (一)統計檢定:
統計檢定傳統方法是,先假設參數適合一些條件,如等於某個數值,
然後抽一樣本和利用這樣本計算出一個測度,(由一些理論方法如類似函數比率檢定所找到的檢定統計量),
把這測度和原先假設的數值比較便可以知道原來假設對不對了。
- (二)估計:
估計是直接猜測參數的真值,由抽樣出來的數值,算出一個測度,用它來估計參數的值。
例如在母數的假設為常態分佈時,我們常用樣本算出來的平均值,用來估計母數的數學期望值,即常態分佈中的μ值。又例如我們也會用樣本出來的方差,來估計母數的方差,即常態分佈中的。
用數學方程式寫出來,我們是說:利用樣本平均數,統計量
(其中xi代表樣本中的數據)用來作測度,來估計母數平均數μ。
或利用樣本方差,統計量
來估計母數方差
至於為什麼要用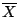 和S2呢,這裏面就涉及了統計一些原理了。 和S2呢,這裏面就涉及了統計一些原理了。
|