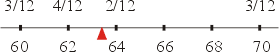�D�����ƾǶǼ��ĤT���ĤT��
�D�@�̷��ɥ��Щ��j�B��u�{�P�z�Ǩt
�E����
�{�N�έp�Ǫ��o�i
���[��
|
�D�����ƾǶǼ��ĤT���ĤT�� �D�@�̷��ɥ��Щ��j�B��u�{�P�z�Ǩt �E���� | |||
|
�{�N�έp�Ǫ��o�i
���[�� |
|
�u�έp�v�o�ӦW�����N�q�]�H�Ӳ��A��@��H�Ө��A�έp�O����譱�M�a�̥ΥH�������I���@�j��Ʀr�F���`�Ѫ��H�����A�o�ӦW���N���ΥH�K�n�M�����@��ƾڦp�p�⥭���� (mean) �P�зǮt (Standard deviation) ���{�Ǥ����������C���O���q�Ʋέp�u�@���H���Ө��A�έp�O�̤p�q�ƾڡ]�˥��^�Ҵ��Ѫ���ƥH���p�w���Y��s��H�p�s�骺��k�C�Ϊ̧�s�q�a���A�έp�����藍�w���p��w�M�����Ѥ�k����ǡC
���M�έp���_���i�l���ܤQ�K�@���ƦܧA�M�Ӳέp�ǥD�n���o�i�o��ܤQ�E�@�������G�Q�@������~�u���}�l�C��F�|�Q�~�N�~�v�������A�έp�ǩM���v�ת����Y���`�K���A�ƹ�W����έp���D����s�������o�A����v�ת��B�ΡA�]����̹ꬰ�e�̪��D�n�u��C
�έp�H����p�U���|�������D�����ײ`�P����G�O�_��������e�禨�~�H�l�ϻP�o���g�����ܡH�i�T�|��U�����|����ӶܡH���F�^���W�z���D�A�ڭ̥����Ѩ�u�N���ʡv���S�����p�H�u�A�ѡv�@�몺���p�A�Ѽ˥��u�����v�s��C�]���A�Ѳέp�H���ұ����o�쪺���׳����O����֩w�i�H�����C�ƹ�W�A�έp�H����¾�d���@�O�q�ץL�ұo���ת֩w���{�סA���O�ڭ̤���H���έp���ʥF�֩w�ʦӻ~�{���έp�ƾǤ��Y�K�A�]���c���έp��¦���ƾǬO���v�סA�����T�Y�Y�۪��Ʋz�ư�¦�M�g�Y�K�ҩ����w�z�C
�@��Ө��A�ڭ̥i�H��έp���D���������G �ԭz�έp�M���ײέp�A²�檺���G�����ƾڡ]�Y�˥��^���B�z�ɭP�w���α��s�骺�έp�٬����ײέp�C�Ϥ��A�p�G�ڭ̪�����u������Y�{�����ƾڡA�Ӥ��dzƧ�G�Ψӱ��s��h�٬��ԭz�έp�C�|�ӨҤl�ӻ��A�̾ڹL�h�Q�~�Ӫ��έp�A�C�~�ӵ��[�����H�ơA�����C�H�b�O���d����ơA�����C�H�C�Ѧb�ت���O�A�Q�~�����@�~�г̰��O���������O�ݩ�ԭz�έp���d��F���O�p�G�ڭ̮ھڳo�Ǧ~�ұo���ƾڨӹw���Ӧ~�i��[���ȤH�ƴN�O���ײέp�����D�F�C�Q�~�e����Ųέp�ҥ��j�h�ͱԭz�έp�A�p���ѩ�p���������A�o�������u�@�j�h�Q�έp����ӸѨM�A�٬��ƾڳB�z�A�Ӥ@��έp�Ѫ����I�O��b���ײέp�C
�j�P���ӡA���ײέp�����T�j���A�N�O���p�A�˩w�M�����P����C Ĵ�p���A�i�T�Q�v��O�_��ij���A�L�Q���p�@�U�i��h�֤H�|�벼���L�A��O�L�H�H����˪��覡�A�߰�100�즳�벼�v���������N���A�ӫ�ھکұo���G���ץi��������h�֤H�|��L�A�o�O���p���D�C�S�p�Y�a�x�D���Q���D�o�ߤ��h�ü���P�~�篻���~�b�O�O�_��R���P�~�篻�j�A�������]����P��R���P�n�A�M��g�L����Ӵ��w�o�����O�_���ߡA�b���Ҥ��A�ڭ̨ä��Q���p����ѼơA�ӥu�O�Q����ƥ��ұԭz�����]�O�_���ߨ�i�a�ʦ��h�j�A�o�N�O�˩w���D�C �٦��A�s�s�y���T���ī~�����X�ؤ�ثe�ҥΪ��o���ī~���ĩO�H�o�O��ܪ����D�C�p�G�ڭ̧�έp�]�Q���g�ѩ�˥H��w�M������ǡA����ڭ̦��G�y�H�Q�E�@�����������y��h�]Sir Francis Galton, 1822��1911�^�M�d���D�ֺ����]Karl Pearson, 1857��1936�^���z���������_�I�C �q���ɶ}�l�A�{�N�έp�z�ת��o�i�i�������|�j���A�b�o�|�j�ɴ��A�C�@���q���O�H�@�찶�j���έp�Ǯa���M�۬����� ��1�C �Ĥ@���q�H��1899�~�����y���mNature Inheritance�n�@�Ѫ��X���Ӯi�} �ǹ��A�ӮѰ��F�䥻�������ȥ~�A�٤o�F�ǥX���έp�Ǯa�d���D�ֺ�����έp�Ǫ�����C�b�����e�A�֤�u�O�b�۴��j�Ǫ��j�dz� (University College) ���Ъ��ƾDZЭ��C���ɡA�o�u�Ҧ����ѳ����έp��¦�v���Q�k�ް_�F�L���`�N�C 1890�~�L���樽���ǰ| (Gresham College)�A�b���إL�i���¥���L�Ʊ����ª��ҵ{�A�֤��F�@���D�ءu�{�N��Ǫ��d��P�����v(the Scope and Concepts of modern Science) �b�L���½Ҥ��L�V�ӶV�j�լ�ǩw�ߪ��έp��¦�A��ӥL���������P�O��έp�z�ת���s�C���[�L������Ǧ����@�ɦU�a�H�̾Dz߲έp�M�^���I�U�u�έp�����v����s���ߡC�g�ѥL���ߪ����ҡA��Ǥu�@�̳v���ѹ�έp��s���P���쪺�Ҧa��Ӧ��������a�V�O�o�i�s�z�שM�j���ì�s�o�ۦU�譱���ƾڡC�H�̶V�ӶV�`�H�έp�ƾڪ����R�ର�\�h���n�����D���Ѹѵ��C
���ۡD�اJ (Helen Walker) �y�z�֤�p�ɭԪ��@�h�c�ơA�Ͱʦa��ܥL����Ʒ~���Ҫ��{���S�� ��2 �C���H�ݥֺ����L�ҰO�o�̦����ơA�L���u�ڤ��O�o���ɬO�X���A���O�ڰO�o�O���b���Ȥl�W�l�m�ۤj����A���H�i�D�ڳ̦n����m���A���M�Q�m���j����|�ܤp�C�ڧ��⪺�j����ñƬݤF�ܤ[�A���̦��G�O�@�˪��A�ڹ�ۤv���G�ڬݤ��X�Q�l�m���j�����t�@�Ӥp�A���h�æo�O�_�b�F�ڡv�C
�b�o�ӳ�ª��G�Ƥ��A���۵اJ���X�u�����H�v�¡A�n�D���ҡA���ۤv���[���ƾڪ��N�q����ö�`��H�ߡA�M�h�ûP�L���P�_���P���H�A�O�_�����v�o�ǴN�O�֤�@�ͿW�㪺�S�x�C
���@
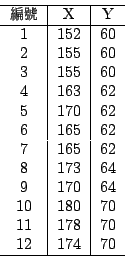
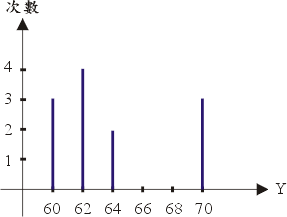
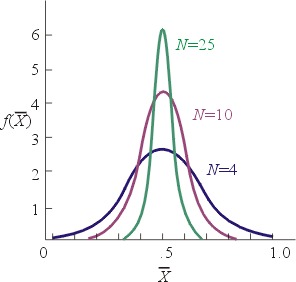
�o�ӲĤ@���q���S�I�N�O�H�̹�έp���A�����ܤF�A�έp�����n�ʳQ��Ǭɩҩӻ{�C�������~�A�b�έp�ޥ��W�]���ܦh���i�i�A�ڭ̧Q�ΤW���o�ӤQ�G�ӤH�������M�魫���ƭȪ����Ф@�dz̰��έp�[���A�䤤���� X �H���������A�魫 Y �H���笰���C
���F��o�ո�Ʊo��@�I�����A�ڭ̧⥦�C���ϧΡC�^�H���ܵ�]William Playfair, 1759��1823�^�Q���{���N�ϧΪ��ܪ��������Ш�έp�Ǫ��Ĥ@�H�C�L���ۧ@�A�j�h������g�پǡA�h�ĥιϧΦp����ϡB���ιϡC�b�ڭ̤W�z���D���A�Φ��ƹϴN��ܲM���a���ܥX�ӡA�Ϥ@�N�O���� X �����ƹϡA�魫 Y �����ƹϤ]�ܮe�����ܡC
�����쪺Ū�̤����@�աC���M�o���ϧί����U�ڭ̪���ı�A���O�p�G�Q��o�Ǽƾڧ�@�B�A�ѡA�ڭ̥��o�i�@�B�άY�Ƕq�Ӵy�z���̡C�b�o���ƶq���̭��n���@�O����Ͷժ����סC�̦��������Ͷժ�����ڤW�i�l���ܥj��þ�A�O��N������ 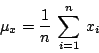
�䤤 xi �N���ܼ� X ���ƭȡAn ���[���Ȫ��`�ӼơA�p��G�o�쨭���������� �䤤 fj �O xj �X�{�����ơA�ù藍�P�� X �ܼ� xj �ȨD�M�C
���]���@�ڵL�������A��W����ܼ� Y ���U���P�Ȫ���סA�åB�]�Q�b xj �B���۽�q
�o�ع省���ƪ������b�H��ڭ̫�ҳs����t�[���ɡA�ܦ����U�C
���M����� (median) �[���i�ভ�w�����A���O���1883�~�~�g�Ѱ����y�⥦�ޤJ�έp�A���������ͶղĤG�ش��� ��3 �C�ҿפ���ƴN�O�Ҧ��[���Ȩ̤j�p�ư_�ӡA���������ӼơA�Y�O���ƭӼƴN�O��Ӥ����ƪ������ơA�b�ڭ̨Ҥl������������Ƭ�165�C
�t�~�٦��@�Ӷ����Ͷժ����O���ơA1894�~���k�ѥd���D�ֺ����Ҥ��СC���Ʀp�G�s�b���ܡA�N�O�X�{���Ƴ��W�c���ƭȡA�p�G��өΨ�ӥH�W���ƭȥX�{���ƬۦP�A���ƴN���Ӧ��N�q�F�A�b�ڭ̨Ҥl���魫�����ƬO62�C
�p�G�ܼ� X �����t�O������١A�Y�䦸�ƹϧ����a��٩�@�����u�A�����ơB����ƩM���ơ]�p���@���Ʀs�b���ܡ^�|���X���@�I�CŪ�̭����`�N�A�ϹL�ӻ��ä����ߡC�]�N�O������٪��ϧΤ]�i�������ơA����ƩM���ƭ��X�����Ρ]�Y�����ơB����ƩM���ƭ��X�ä��O�ҹϧά���١^�C
��j�h�ƪ��ت��Ө���N�����ƬO�̱`�Ϊ������Ͷմ��סA�o���M�����Dzz�W���N�q�C���M���ɭԭp��۷��O�ɡA����Ƥ]�������u�I�A�������ּƷ��ݭȪ��v�T�C�Ҧp�b�ڭ̪����D���A�Y��@�Ө���180�������H�����@��200�������H�A�����ƴN�|����ܤj���v�T�A�Ӥ���ƫo���M���ܡC
�䦸�ڭ̽ͤ@�U�u���t�v(dispersion) �����סA���O�ƾڥH�����Ƭ��ǹ������{�ת����סC�̦��o�ش��פj���O����]Bessel�^��1815�~�Ω����Ѥ�ǰ��D���u�i��~�t�v�C�ثe�̳q�Ϊ��O�u�зǮt�v�m�A�o�ӦW���O1894�~�d���D�ֺ����ҳСC
�����ܼ� X ���зǮt�w�q��
![\begin{displaymath}
\sigma_x = \big[\frac{1}{n} \sum^n_{i=1}(x_i-\mu_x)^2 \big]^{1/2}
\end{displaymath}](img7.gif)
�ѳo�Ӥ����i�H�ݥX�Y�ƾګD�`�����A
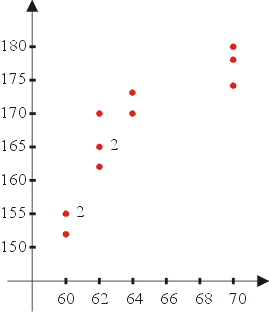
���F���Ь������[���A�ڭ̦^�Y�A�J�Ӭݤ@�U���@���������M�魫�A�ƭ���ܳo����ܼƦ��G���Y�ج����s�b�A�ھڱ`�ѡA�����H�q�`�n��G���H���A�b�o�Ǽƾ��Iø�b�������Ъ������W�A�i�H�ݥX���̤��������Y�A�٬����G�ϡ]�Ѩ��ϤT�^
�p�G���̤������u�����Y�A�h�I���ͦV�|�e�{�b���u������C
�b�Q�E�@�������A���H�ݰ����y��h�o�ب�ռƾڤ��������Y�O�_�i�H���סH�L�Q�X�F�������[���C���O�ڭ̲{�b�ҥΪ������Y�ƣl �o�O�d���ֺ����ҳСA��w�q��
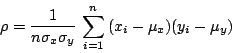
�g��²�檺�N�ƹB��A�ڭ̥i�H�ҥX�l���ƭȤ��� -1 �P +1 �����A0 �Ȫ��ܨS�����u���Y�s�b�A
�����y�O�ۦW���t�ƽת̹F���媺���ˡA�����F���尵�L�@�Dzέp�u�@�C �ڭ̦b�W�`������L�������������s�A���O�Юv�̳̤��|�ѰO�����^�m�O�L���Ч⦨�Z�����P�`�A���u�ԤW���Y�C
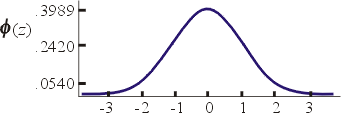
�`�A���u�ܤ֥i�l����1733�~���Ь����]Abraham De Moivre�^�����ҡA�O�@�Ӳέp�W�D�`���Ϊ��[���C������{����
�䤤 �g �M �m ���ѼơA�ꥩ���������ƩM�зǮt�C�@��H����N�u���Φ��u�v���Q�����`�A�A�ƹ�W�o���[���ä����T�C��L��ƨҦp
�`�A���t���u�I�O���ר䥭���� �g �M�зǮt�]
�����b���������t���ɭԡA�ڭ̴��g�����N�����ƥi�H�ݦ��O�`�譫���� 1 ���������I��t����q���ߡC��~�ڭ̴��쪺�`�A���u�O�@�ӳs����t���Ҥl�A�̾����覡�A�ڭ̥i�H��`�A���t�P�@�ڲz�Q�ƦV��ݵL�������譫�� 1 �Ө�K�h���̨M�w�`�A���t����� f ���ܰʤ��G���ά��p���C�̾ڷL�n���A�o�ر�Ϊ���q���߬O
�o�Ӥ������O�ڭ̥Ψөw�q�s����t�������ƪ����l�C�γ\�ܥX�H�N�~���A�ä��O�C�@�s����t���������ơA�]���W�����n�����ɥi�ण�s�b�C�Ҧp�_����t�A���{���� �N�O�@�ӥ����Ƥ��s�b�����t�A�����쪺Ū�̥i�յ����ҥ��C
�P�z�A�̾������ܼƪ��зǮt�����A�ڭ̥i�H�w�q�X�s����t���зǮt��
�p�G�γo��Ӥ����ӭp��@�U�`�A���t�������ƩM�зǮt�A�g�Ѭ۷�²�����n���B��i�H�o�X���̤��O�O������ӰѼ� �g �M �m�C�����H�~�A�����y�B�ֺ����M�L�̪��u���{�v�ٳХX�j�k�[���M�d�����C �j���b1915�~�A�@�ӷs�W�r�X�{��έp�ɡA�O���]Ronald Aylmer Fisher, 1890��1962�^�A�L�b�Ӧ~�o������˥������Y�Ʋέp�q����T���t���פ�ɶi�J�έp�v���ĤG�ɴ��C�ۥL���@�t�C���פ�M�M�ѵ��έp�լd�a�Ӥ@�ѷs�ʤO�C���H��ڭ̦p���ұĥΪ��έp�z�ת��b���k�\���O���N�A�b�O��M�L���P���̨��V�����N���A�]�A�A�Ω�p�˥����έp��k���o�i�A�o�{�\�h�˥��έp�q����T���t�A�����˩w�����h��²�����z�A�ܲ��Ƥ��R���o���M��@�Ӹs��Ѽƪ��Ʋz�έp�q���p����˪��ǫh�����СC �ڻ��O���O�Ӧ������Ĥl ��4 �A�b�ܤp���ɭԴN�w��q�p�y���T�������}�`���ǰݡC�L���磌�z��Dz`�P����A1912�~�ۼC���j�DZo��Ѥ�Ǫ��Ǥh�Ǧ�C�Ѥ�Ǥ����~�t�� (theory of errors) �ϥL��έp���D�o�Ϳ���A�ڭ̴���1915�~�L�i�J�έp�ɦ]�����~�L�o���@�g����˥������Y�ƪ����t���峹�C�o�g�峹�ҩl�F��U�ؼ˥��έp��T���t����s�A�O��b�o�譱��ɲ��W�C�b�o�譱����s�A�L�`���ӾU���X��ı���ɡA�o�X���ܦh���G�A��Ӹg�X�ӻD�W�@�ɪ��̳ǥX�ƾǮa����s�A�ҩ��F�䥿�T�ʡC
�O���٦��ܦh��L���^�m�A�����ڭ̴�����L���ФF�@�˥��έp�q�O�_���@�Ӹs��Ѽƪ��n���p�q���P�w�ǫh�A�]�A�F�@�P�ʡA�IJv�ʩM�R���ʵ������N�O�b1921�~�@�g���n���m�����쪺�C�b�o���峹���A�L�ٴ����г̷����p�q (maximum likelihood estimation) ���[���C
1919�~�O�����}�L�b���DZмƾǪ��u�@�A���ù�˴��o�A�~���篸 (Rothamsted Agricultural Experimental station)�A�b�o�إL�o�i�X�{�b�@�ɳq�Ϊ���˧ޥ��M�H���{�ǡC �L���⥻�W�ۡmStatistical Methods for Research Workers�n�M�mDesign of Experiments�n���O��1925�~�M1935�~�X���A���έp�����j���v�T�C��̪��ĤG�����C�J�m�ƾǥ@�ɡn ��5�A �b�o�g�D�`�ޤH�J�Ӫ��峹���A�O�즳�@��k�h�n�٦o�����X�o�����������O�b�w�����e�Τ���[�J���A�ӫ�L�y�z�@�ع���p�����ҩ��Χ_�w�Ӥk�h���n�١C
���F�Q��������s�骺���D�A�ѹ�Ϊ��[�I�ӬݡA�ڭ̥����Ѹs�餤����˥��A�M��̾ڼ˥��Ҵ��Ѫ���T���ץ���C����үA�Ϊ��p���駡�� �g �M�зǮt �m ���O�����A���]���@�Ӽ˥��Q�ܾA���a��X�]�p���k�O�@�ӫܭ��n���έp���D�^�A�̾ڼ˥��i�H�o�X�۷��n������ѼƩάY�q�����p�ȡC
�����ڭ̴�����O�����X����Ѽƪ��n�˥��έp�q���P�O�ǫh�A�ڭ̥u�O��²�n�����X�A
���Y (x1, ![\begin{displaymath}
\overline{X}=\frac{1}{n} \sum^n_{i=1} x_i \quad \mbox{{\font...
... \big[ \frac{1}{n}\sum^n_{i=1}(x_i-\overline{X})^2 \big]^{1/2}
\end{displaymath}](img25.gif)
�γo�Dzέp�q�H���p �g �� �m�A�|�����O���ҭq���j�����ǫh ��6�C
�p�G�ڭ̥Ѥ@�Ӹs����X�ܦh�ռ˥��A�åB�C�է��p��
�^�Q�зǮt�����n�ʡA�ڭ̪����O���˥��j�p�V�j�A�h
���������w�z���@�q�۷������o�i�v�A1773�~�Ь����ҩ���Ĥ@�اΦ��Y�Ҽ{�Y�w���u����إi��X�{�����ΡA�ڭ̦b�e���һ����Φ��O1922�~��w�f (J.W.Lindeberg) �ҭz
��7
�C��ӫX��ƾǮa�Ʀܵ��X
�έp�H���ٳo�ذ��D�������˩w�A�ڭ̥����˩w����
�ڭ̦A�^�Y���@�U���]�s�s�{���зǮt �m ���ܪ��~�t���v�C�ƹ�W�A�o�� �m �w���O�@�Ӥw���ơA���O�ڭ̥i�H�p��X�˥��зǮt S�A�b1908�~�ƾǮa����S�]William Gosset�^�H Student �����W�o���L�o�{���έp�q
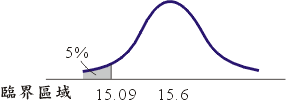
�ĤT�Ӯɴ��H���b1928�~¿�ҡ]Jerzy Neyman�^�M��ڡD�ֺ����]Egon Pearson, �d���D�ֺ������l�^���@�P�פ�h�g���o�����}�ݡA�o�ǽפ夶�ЩM�j�սѦp��w���D�����ĤG�ؿ��~�A���窺�˩w�O�M�H��϶��������[���C�b�o�����A�u�~�ɶ}�l�j�q�ĥβέp�ޥ��A�ר�O�P�~��ި�����έp�C�åB�ѩ�H�̹�լd�u�@���P����ɦV���˲z�P�ޥ�����s�A1928�~¿�ҩM��ڡD�ֺ������פ嬰�˩w�P���p�z�ױa�Ӥ@�ع�s�������C�]�A��\�h�O���������X���Q�k�����s�[�H��z�M�ץ��A�Ҧp�b��÷�s�y�Ӫ����D���A�ڭ̦����o�쪺���O�G�Y�@�˥����˥������ƭȤp��15.09�h��o���� H0�C¿�ҩM�ֺ������X�p�U���������D�G������ڭ̭n�]15.09�H�����{�ɰ�H������0.025�b���t���u���������n�M0.25�b���t���u���k�����n���u�����v(two tailed) �{�ɰϰ�H
�����{�ɰ�ɥ����Ħ�طǫh�H�ڭ̥����n�Ϊ�ı�٬O���Y�Ԫ��ƾǡH�ڭ̱o��p�ϤK�����ײo�A���ؤ��P���A�����~�A¿�ҩM�ֺ����R�W���Ĥ@�ؿ��~�M�ĤG�ؿ��~�C¿�ҩM�ֺ����`���L�̪��o�{�k�Ǧ����U�z��h�G�b�Ҧ��㦳�ۦP�Ĥ@�ؿ��~������]�{�ɰ�^���A�ڭ̿�Ψ�̤p�ĤG�ؿ��~���{�ɰ�C
�ϤK
���M����h�����ά۷������A¿�ҩM�ֺ������v�T�ϥ���h�Ψ�������˩w�O��Ʀ� �����n���έp�����A�åB�o�i�X�Q�׳o�����D���@��ƾDzz�סC
�Ͳ{�N�έp�Ǫ��o�i�A�ꤣ�ण���ؼw�]Abraham Wald, 1902��1950�^ ��9 �A�_�h���w��o�����ơC�ؼw���Ĥ@�g�פ�����ثe�`�����έp�{�Ǣw�w�v����� (sequential sampling) ���X�{�ĥ|�ɴ����}�l�C�o�g1939�~���פ�O�ؼw�@�s��פ媺�_�l�A���������L���зs�O�B���A�p�ɫo�ѩ����Ʀ���D�R�C�ؼw�̤j���^�m���@�O�L���Ф@�ع�έp���D���s�ݪk(1945)�A���N�O�H�什���[�I�h�B�z�έp�譱�����D�A�o�N�O����Һ٪��έp�M���z�� (statistical dicision theory)�C�q�o���[�I�A�έp�Q�����H�۵M����⪺�什�����N�A�o�O�@�Ӭ۷��s�q���z�סA���M���o�A��۷��������ƾǡA���O���ߦӽסA�ڭ̥i�H���j�����ثe���έp��s�H���o�{�ĥγo�طs�[�I�D�`�z�Q�C�ؼw��έp�z�o�i����V�����j���v�T�A�L���u���{�v�̦h��������έp�ɪ���S�H���C
�ؼw�ϥͦbù�����ȡA�O���Ϊ� (orthodox) �S�ӥ@�a�A�ѩ��v�ЫH���A�ϥL���Ш|�����|����Y�ǭ���A�ӥ����a�ۭ����ɡC�L�ۭת����G�����ƺ��B�S (Hilbert) ���mFoundation of Geometry�n���X�����Ȫ����ѡA�L����ij�C�J�ӮѪ��ĤC�����A�o�@�ƹ�R����ܤF�L���ƾǤѽ�C��ӵؼw�i�J���]�Ǥj�ǨåB�b�ȭפF�T���Ҥ���N�o��դh�Ǧ�C�b�o�Ӯɴ������a�Q�A�ѩ�F�v�W���]���ϥL�L�k�q�ƾdzN�u�@�A�u�n�����@�Өp�H¾��A¾�d�O���U�@��Ȧ�a�W�s�����ƾǪ��ѡA�L�]����g�پDz`�P����A��Ӧ����g�پǮa���ڴ��Z (Oskar Morgenstern) ���˫H�U�z�C���P���ð� (John Von Neumann) �@�P�X�@�q�Ƭ�s�ó��w�F�什�� (game theory) ����¦�C
�ؼw�b�G���j�ԫe��F����A�L�������M�n�f�����S���k�X�ӡA���G����Ǻ骺�˴��СC�ؼw�ѩ��g�پǪ����챵IJ��έp�ǡA�v����V�q�Ʋέp�Ǫ���s�A���[�������@��ǥX���z�ײέp�Ǯa�C���F�έp�M���z�פ��~�A�ؼw��έp�٦��ܦh���n���^�m�A�b���ڭ̴��X�D�n���@�ӡA�N�O�v�����R�C���M�o�Ӳz�ץi�ण�O�L�ҭ��СA���o�O�L�o�i������(1943)�C�o�ӧޥ��b��֥Ͳ��s�{������˼Ƥ譱�D�`���n�A�G���j�Դ������Q�C�����K�C
�{�b�ڭ̥H�u�~�譱���~��ި���D���Ҩӻ����v�����R���[���A�b�v����k���o�����e�A�зǪ���˵{�ǬO�ѻs���~������w�q���˥��A�M��̾ڼ˥����ҧt���}�~�ƪ��h��P�w�����Ωڦ��ӧ�C�o�ص{�ǩ����F����s���~�媺�u�H��T�i�Ѧb��˹L�{�����}�~�X�{�v���j�p��o���ƹ�C
�b�v����ˤ��A�ڭ̧��˹L�{���i��o�ͪ����p�����T���G
�o�T�Ӱϰ쪺�����ǫh���Ҥ��\���Ĥ@�ؿ��~�M�ĤG�ؿ��~�өw�C�b���Ҥ��A�b�d��Ĥ��Q�ӻs���~��~�P�w�����C
�ѹϧΤ��i���A�o�ة�ˤ�k�i��ܧִN��M�w�O�_�����A�]�i��b�����ϰ찱�d�ܤ[���ɶ��A���O�ؼw�ҩ������Ωڦ����M�w����B���F�������v��1�A��ڸg����ܳv����˩M�DzΪ��T�w�˥��j�p���{�Ǭۤ�b��˶O�Τ譱���i�`�٤@�b�C
���F�W�z�|�j�έp���~�A1933�~�X��ƾǮa�_����ù�� (Kolmogorov) �o���mFoundation of the theory of probability�n���έp�Dzz�׳��w�F���¦�C�b�έp���Χޥ��譱�A�q�l�p������o�i�M�ϥάO�@�j���R�C�Q�E�@�������}�l�A����H�f�լd�� (U.S. Census Bureau) �C�Q�~�|��@���H�f���d�A��ӡA�ѩ�H�f�����W�A�H�f�լd���o�{�L�̤w�V�ӶV�L�k�B�z�һ`��������ƾڡC�P����� (Herman Hollerith) �Q�X�\�h�Q�Υ��եd�� (punched card) �O���ƾڪ���k�A�åB�o�������Ū�o�ǼƾکM�B�m��T (Information)�A�b�P���ɤU�A1894�~�H�f�լd�����u�@�Q�Υ��եd�MŪ�d���A�������֮IJv�C���M1890�~�H�f�լd�ɡA����H�f��1880�~�W�h�F���ʤ����G�Q���A���O�u�@�����ҶO���ɶ��o�Ȭ���T�����@�C
�q�l�p�����G���j�ԫ�o�i�@��d���A1950�~�ấ�i�J��ζ��q�C�p������X�{�����ϲέp�p��u�@²�ơA�ӥB�ֱ��C�ר�O���F�έp���M�{�� (Statistical package) �H��A��K�A�u�n���D���ĥΦ�زέp��k�N��ϥΡC1972�~�f�� (Heweleit Packard) ���q�o�i�X�x�W���p�⾹ (calculator)�A���@��p�έp���D���ѨM�A��O��K�A�����]���έp���D�S�a��p������ߥh�C
�έp���@��Ǥ�k�A��i���νd��A�M�Φ۵M��ǤΪ��|��Ǫ���ӻ�줤���\�h�����A�j�Z�A�~�B�u�~�B�ӷ~�B�Ш|�B���ġB�F�v�B���|�B�g�ٵ����\�h���D�L���A�X�ĥβέp��k�B�z�A�έp�ǶǤJ�ڰ����w���۷��ɤ�A���O�ڰ�ثe�٥u���F���������������A�����u�ӥ��~��~�����M�]�������D��Ǻz�A���O�j�h�������βέp��k�C
|
��~�j�M����r�G �D������ �D�зǮt �D�έp�� �D���v�� �DGalton �DKarl Pearson �D����� �D���� �DBessel �D���� �D�����Y�� �D�`�A���u �DDe Moivre �D�O�� �D���������w�z �D�����˩w �DHilbert �DVon Neumann �D�什�� �DKolmogorov |
|
|
|
|
�]�Y�������B�ðݡK�K�A�i�H�b�� �d�� �� �g�H ���ڭ̡C�^ |
|
|
|
EpisteMath (c) 2000 ������s�|�ƾǩҡB�x�j�ƾǨt �U�����峹���e���ۧ@�v����ۧ@�H�Ҧ� |
| �s��G�x�� �A ø�ϡG²�ߪY | �̫�ק����G4/26/2002 |