�D�����ƾǶǼ��ĤG���ĤT��
�D�@�̷��ɥ��Щ�x�j�ƾǨt
�E����
���v�@��
������
|
�D�����ƾǶǼ��ĤG���ĤT�� �D�@�̷��ɥ��Щ�x�j�ƾǨt �E���� | |||
|
���v�@��
������ |
|
���v�ת��@�ӵo���a�O�O�z�έp�ǡF���A�O�z�έp�Ǫ������A�����v�ת��DzߡA�j���U�q�I
�u1 ���o 70 ���A2 ���o 81 ���v
�P
�u2 ���o 70 ���A1 ���o 81 ���v
�õL�ϧO�F���O�A�N�ǥͪ��߳��A�o���M���ϧO�A���Ѯv�A�ϧO�N���j�I�ˬO���X�ӤH 81 ���A�X�ӤH 70 ���A�٦��I�ϧO�I
�٦��A�n�O�����@�I�O�GX ���w�q��A���a�O 1 �� 50 ���۵M�ơA�o���ӭ��n�C
���ǥͪ��a���A�ڭn���H�L�l�k�����Z�N�n�F�F���ժ��A�@�ӭӾǥͪ����Z�L�o���|�@��ť�F�L�n���D�̭��n�o�]�̰_�X�����ơG�ҡB�j��p��H�A�B�O�_�Ѯt���j�H�]�]�\�ӦҼ{�u��O���Z�v�H�K�K�^�C
�ժ����@�w���N��@��Ţ�Ϊ��A�]�w�ʪ��^���k�A�p�u�j��ܦn�A�Ѯt���j�v�A�L�n�@�ӧ��T���A�]�w�q���^���k�F��O�A�ڭn���L��ӼƦr�G�ҡB�N���� 1 �C�A�B�Ѯt�� 2 �C
�q�`�ĥ�

����סA��O�A���ժ������i�A�N�O�u���Z������Ҧ��Z��
![\begin{eqnarray*}
A.M.(X)&\equiv&\sum_1^N\frac{x_i}{N}\\
S.D.(X)&\equiv&\sqrt{N^{-1}\sum[x_i-A.M.(X)]^2}\\
&=&\sqrt{{\mbox{Var}}X}
\end{eqnarray*}](img6.gif)

�ڥ����A�j�ճo�@�I�G�ĥγo�ءu
�A�������s���F X=x ���W�v (frequency)�C�����N�q�ܩ��աA�������F���l�e���I�ƹ�W�ڭ̭p�� �Ъ`�N�G�Y �p �O�� �h 3
�Ҹզ��Z�A���M�b 0 �P 100 �����G
�o�N�O�ۦW���]�ӥB�]�X�G�L�᪺�Atrivial�^Markov �������C
�ڷQ�ҩ��N�i�H�٤F�F�ѡu�ڭ̯Z�v���Ҥl�N�ܩ��դF�I
�ˬO�������Ѥ@�U�G
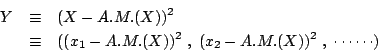
�h Y �N�O�Ӳέp�ƾڡA���D�t�A�]�� Markov �������� Y �A�ΡI�]�N�O���G�� k>0�A�]��� k>1 �~����I�^ 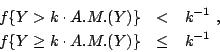
���O�A�өw�q�A �ӥB�O ���O �N���� �]����(Chebyshev ������)�G �� �ڭ̦b�o�إ����A���A���O�z�έp�F�A�N�����v�רӡI
���F�����o�@�I�A�ڭ̷Q���o�ر��ΡC�h�~�ڰ��F���㪺�����˦��@�i�i�d���A��F�o�@�~�סA�ڨM�߰��Ӥ��t�d���Ѯv�G�Y�A�O�Ӿǥ͡A�ڽЧA��@�i�d���A�N�����A�����ơC
�o��@�ӰO�z�έp�N���F���v�פF�I�p�G�A�h�~�� 4 �ӤH���Ƥ��줭�Q���A����A
�{�b�A�A�����Ƥ��줭�Q�������v�N�O 0.08�A���y�ܻ��A�u�۹��W�v�v�令�u���v�v�A�βŸ� P ���ܡG
P{X<50}=0.08
�p�G�h�~�� 6 �ӤH���ή�A�Y f{X<60}=0.12�A�h�{�b�A���ή檺���v�O 0.12�A�Y
f{X<60}=0.12
���M�A�{�b�� X �q�u�έp�ƾڡv�令�F�u�H���ܼơv�A�H�۾��|�]�A���B��^���ܪ��ơF�t�~�A�u��N�����vA.M.�A�]�令�]�ƾǡ^����� E�F�p�G�h�~���Z������ A.M.(X)=74 ���A�h�A�]�{�b�^������ȴN�O
E(X)=74 .
���y�ܻ��A�ڭ̦���²�檺�p�r��ӹ�ӳo��ػy���G
�i�O�A�ڭ̤w�g�j�չL�F�A�o���v�O�ꪺ�C�U�@�]��ꤣ�O�u�U�@�v�A�ӬO�u���Q�@�v�^�A�A��쨺�i���ή檺�d���A���� X<60�C�]�Ҧp X=50 �a�^�A�p���B�𤣦n�A����o�Ǵ���ȡA�ξ��v�A�������F�A�����I���u�ڤή檺���v���F 98
����ڭ̫������u�@�ƥ��v�� p�v�O�H���٦� Bridgeman ���B�@�[ (operationalism)�A�ҥH�ڧ�Ĥj�ƪk�h�Ӹ����C
�]�z�^�j�ƪk�h�G���]�@�ƥ� A �o�ͤ����v�� p�A���]�ڭ̯���@�A�a���Чڭ̪�����A�[��P�˪��{�H�A�C�����G�m���ۦP�]���|�ۦP�^�A�ӥB�@�����������ۨS�����p�A�@�F n ���A�䤤�� k ���o�ͤF�o��ƥ�F�ڭ̭p��o�ͪ��۹��W�v
�ڭ̥��j�դ@�U�G���୫�ơ]�W�ߡ^�a�@���窺�Ʊ��A�����v���Ӧ��N�q�I
�ڦA��W�z���j�ƪk�h���s�@�U�G
���ΡG�p�G�A���D E(X)=84�A���w������k�O�ЦѮv�]�ڡ^�P�N�G��ܦh���A�]���h�ڳW�w��X�ӭn��^�h���s��^�C�Υ��̪�����
|
��~�j�M����r�G �DLebesgue �DChebyshev������ �D���v�� �D�H���ܼ� �D����� �D�j�ƪk�h �D��N���� �D�зǮt �D��t |
||||||||||||||||
�q�`���j�ƪk�h�A���A�[�W�Ǥ����n������A�o�DZ������M�����n�A���b��ǮɡA�O�ܦ��Q���e���]
�ѩ�� Xi ���ۿW�ߡA
�G �� Chebyshev ������ �G
|
|
|
|
|
�]�Y�������B�ðݡK�K�A�i�H�b�� �d�� �� �g�H ���ڭ̡C�^ |
|
|
|
EpisteMath (c) 2000 ������s�|�ƾǩҡB�x�j�ƾǨt �U�����峹���e���ۧ@�v����ۧ@�H�Ҧ� |
| �s��G���H�� | �̫�ק����G4/26/2002 |